Localizing and Navigating in Semantic Maps Created by an iPhone
This project creates semantic maps from iPhone data and uses Adaptive Monte-Carlo Localization (AMCL) to localize an autonomous wheelchair within them.
Visit this project’s Github here.

Table of Contents
- Introduction
- Mapping on the iPhone
- Semantic Mapping
- Localization
- Navigation
- Future Work
- Acknowledgements
Introduction
The motivation behind this project is to support users of the LUCI autonomous wheelchair. The idea is to have a friend or caretaker use their cellphone to create an accurate semantic map of their home or a public space. The wheelchair can then use this map to navigate to different locations within the space. For example, if a user wanted to go to the kitchen, they could select the kitchen on the map, and the wheelchair would navigate to that location autonomously.
I focused mainly on creating the semantic maps from the iPhone, and localizing the wheelchair within these maps using Adaptive Monte-Carlo Localization (AMCL) localization. The main challenge was to be able to localize with sensors that are different from the ones used to create the map. The LUCI wheelchair is a power wheelchair with a sensor stacking including three Realsense RGBD cameras which each provide an accurate infrared 3D point cloud and wheel encoders which are used to provide odometry. A 2D lidar scan is generated from the 3D point clouds from the front right and front left camera, and is combined with wheel odometry to localize the wheelchair in the map.
Below is a high level visualization of the project’s flowchart:
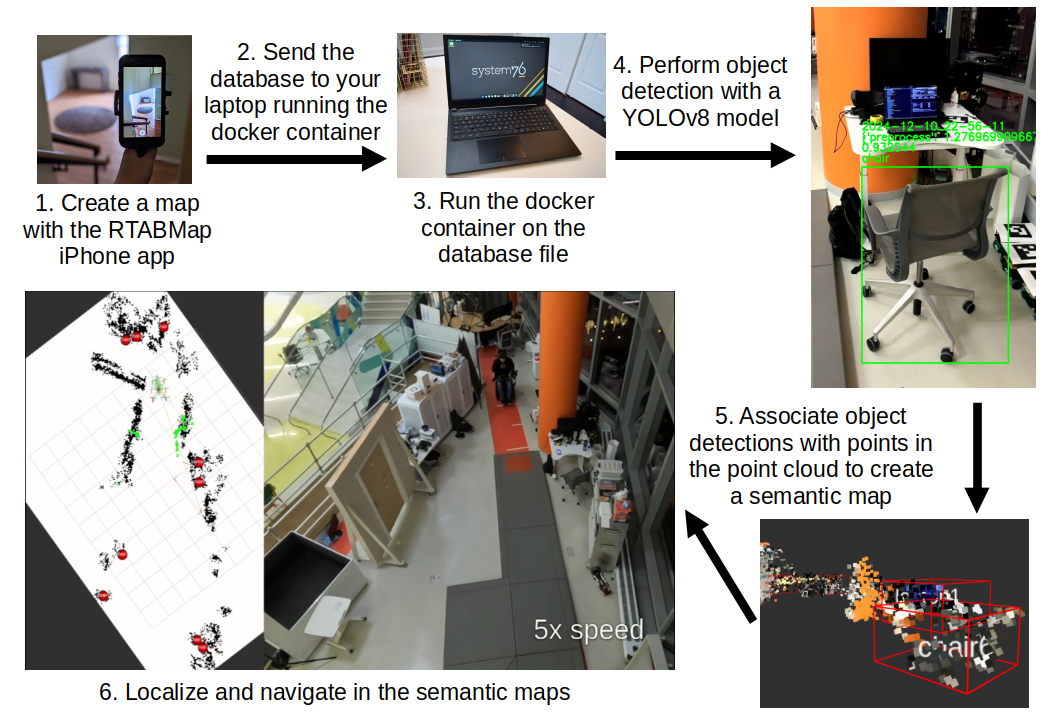
Mapping on the iPhone


I used the RTABMap iPhone app to allow users to create maps of their environment. This application is robust, easy to use, and runs very smoothly. Sideloadable verions of this app are available for Android. I created a dockerfile that builds a CMake package I wrote to process the information from saved RTABMap database files to obtain a 3D point cloud in PCL format, RGB images, depth images, and camera calibration information. This package is specifically designed to process database files created by the RTABMap iPhone app without LIDAR. Databases created using LIDAR can successfully be processed, however it is much slower. Using LIDAR with the RTABMap iPhone app creates a 3D mesh of the environment, and eventually I will add support for using and visualizing this 3D mesh.
RTABMap itself only produces the 3D point cloud and the RGB images through VIO SLAM. I create the depth images by using the iPhone’s intrinsic camera matrix to project points in the 3D point cloud onto the image plane at each step in the camera’s pose graph. Pixel information from the RGB image is also used to give color to the 3D point cloud. Below is some pseudo-code that shows the math behind this process:
std::map<std::pair<int,int>, int> map
for point in point_cloud:
p_transform = point * Tcw.inverse()
x_coord = (f_x * p_x) / p_z + c_x
y_coord = (f_y * p_y) / p_z + c_y
if in_bounds(x_coord) && in_bounds(y_coord):
map[{x_coord, y_coord}] = point_index
We’re solving for the pixel coordinates of the point, u and v.

Since the point from the point cloud we’re considering is transformed into the camera frame, the extrinsic matrix is the identity matrix and the scalar “s” is 1.
Here’s what it looks like when all images are put together in sequence:

Semantic Mapping
After extracting and saving the information from the database, object detection is performed using a YOLOv8 model that’s run by launching the python interpreter from C++ with pybind 11 for each pose in the camera’s pose graph. Points from the 3D point cloud are projected onto the image plane using the iPhone’s intrinsic camera matrix, and points that are within the bounding box of an object are assigned to and labeled with the object’s class.
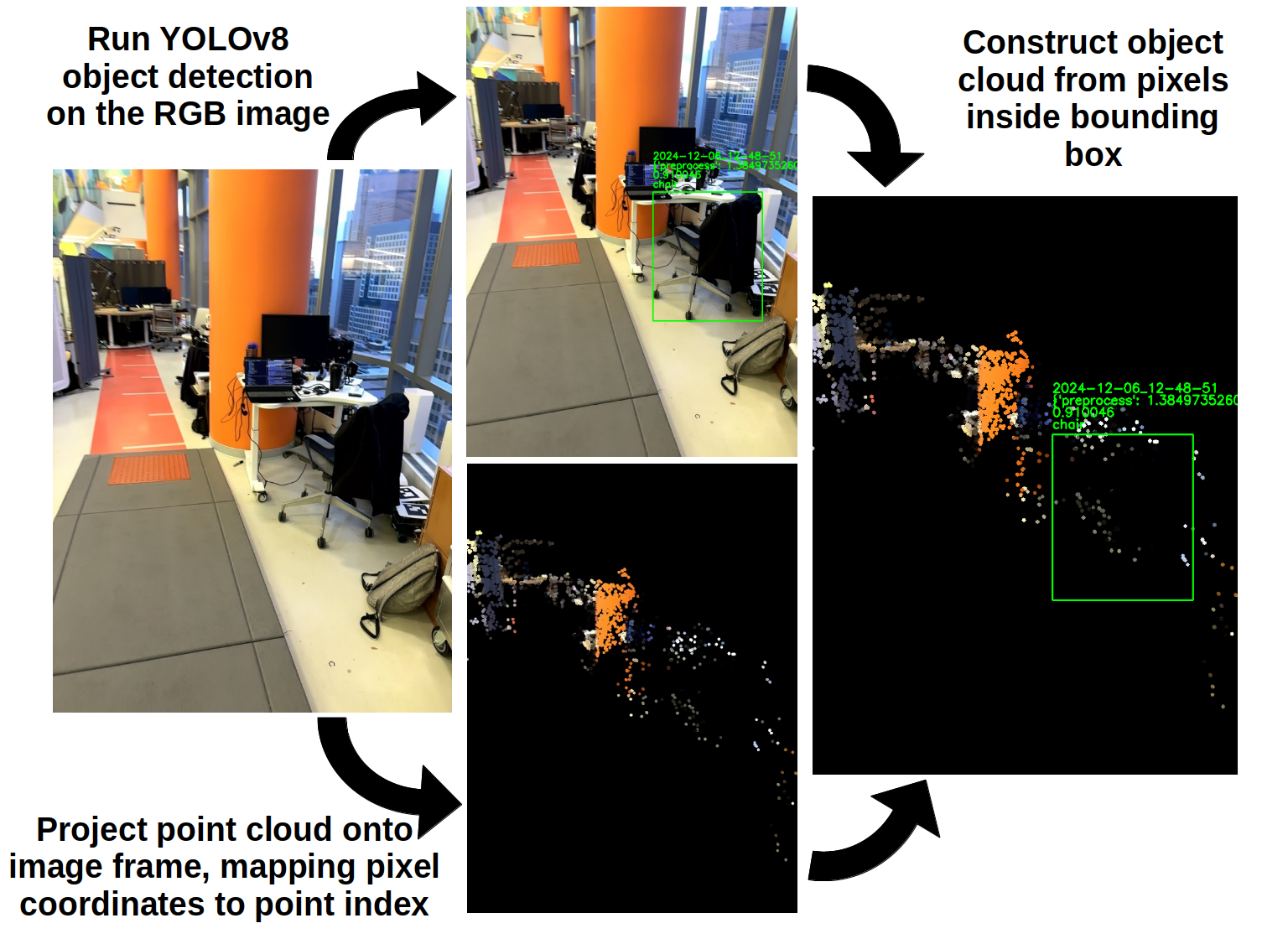
Objects are represented by 3D point clouds, and the centroid of each point cloud is used to represent the object’s position in the map.
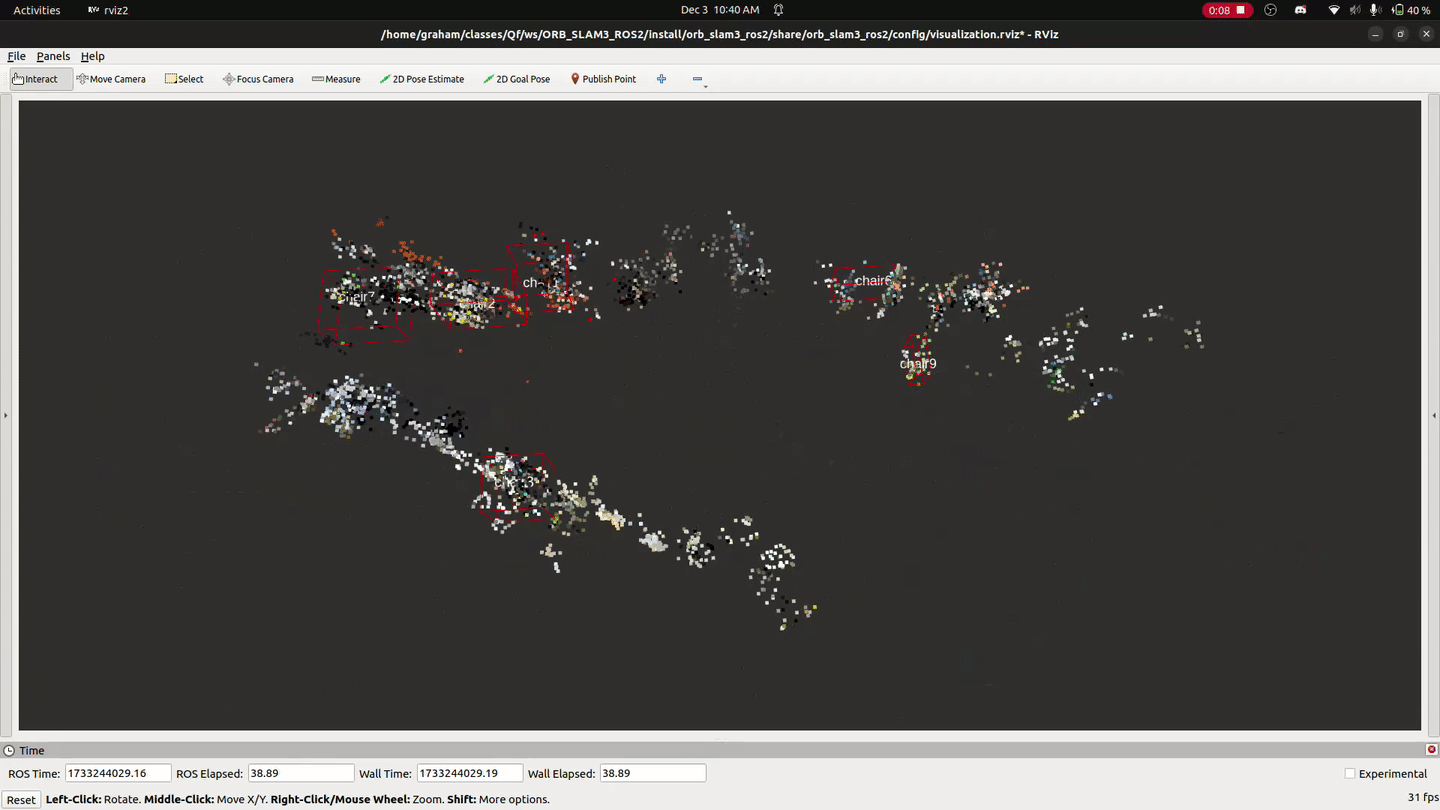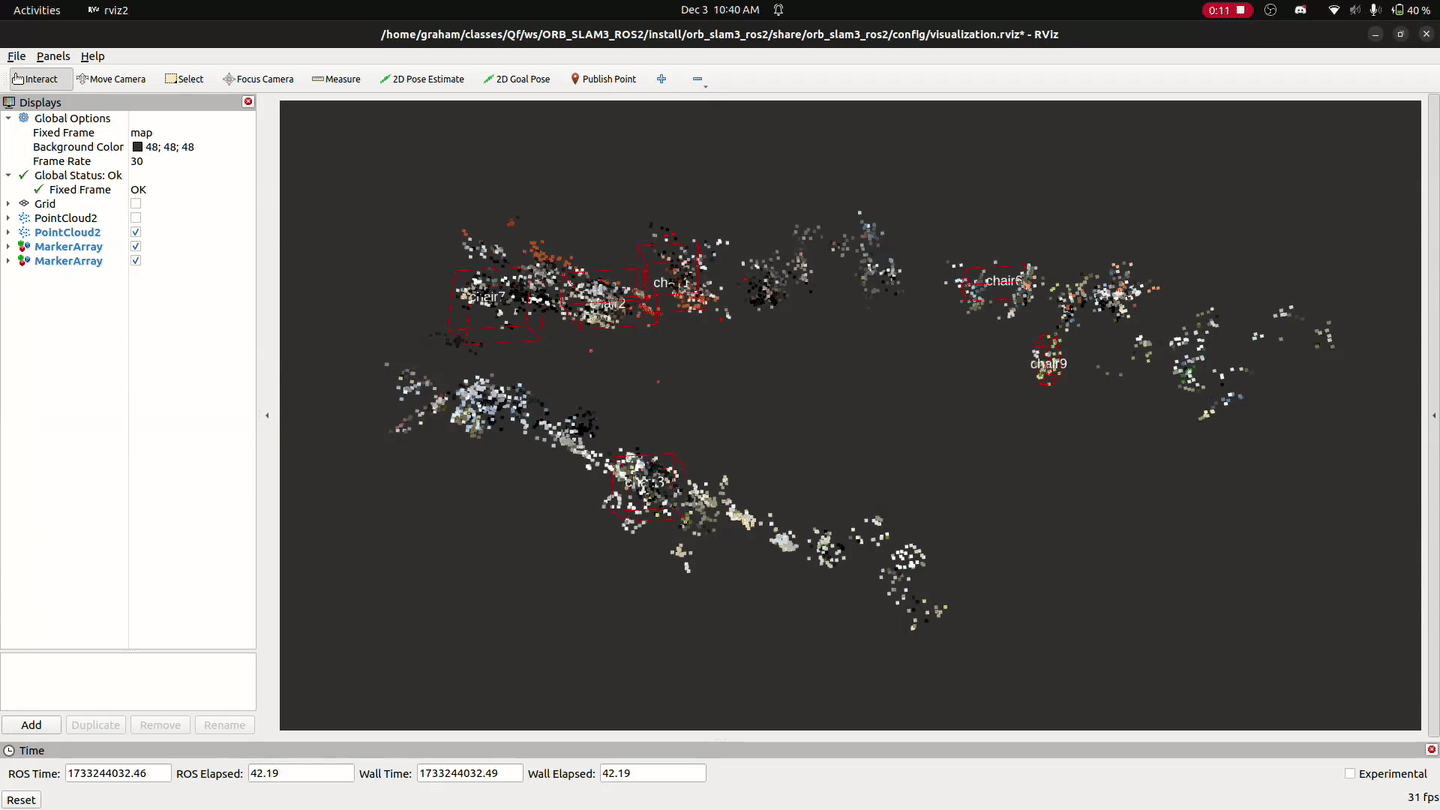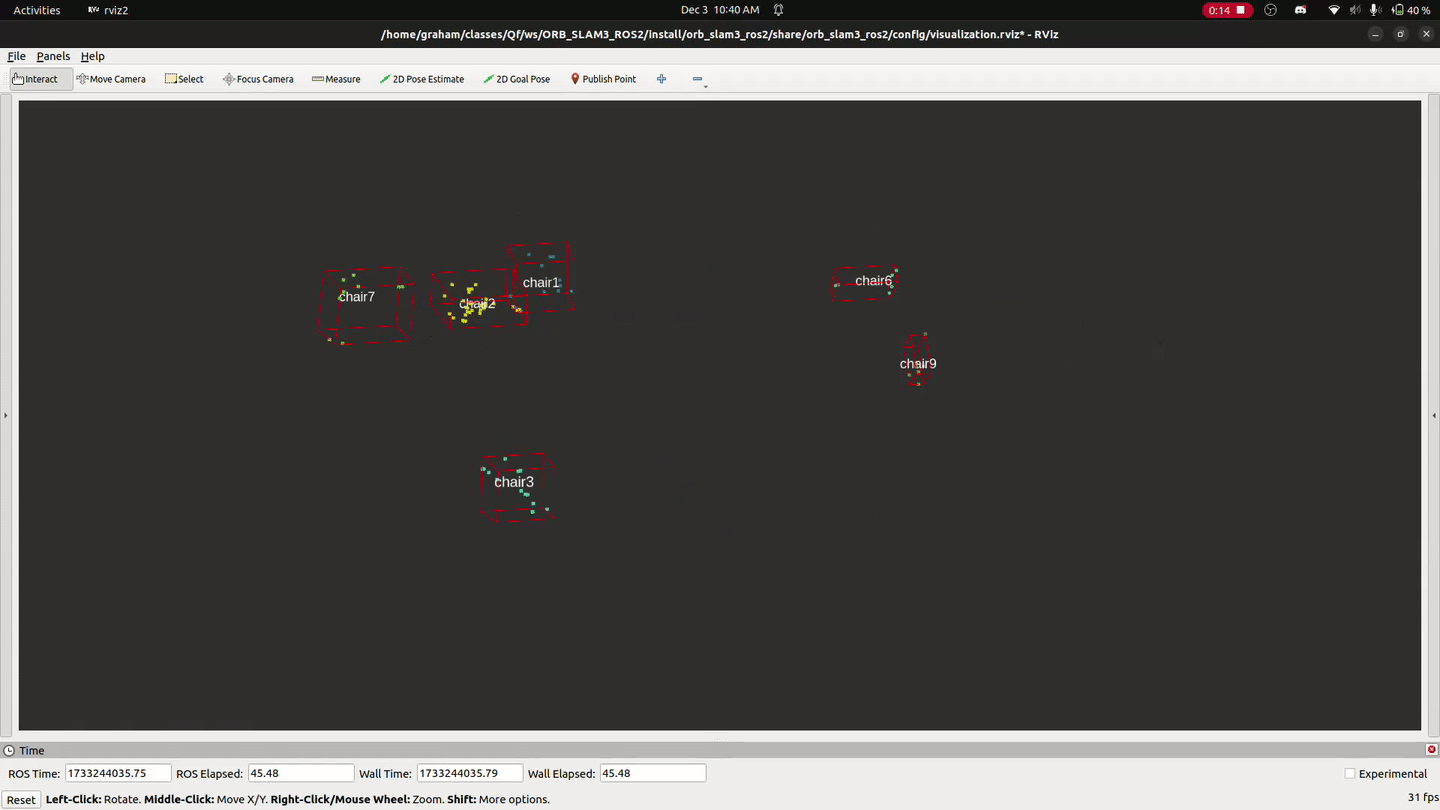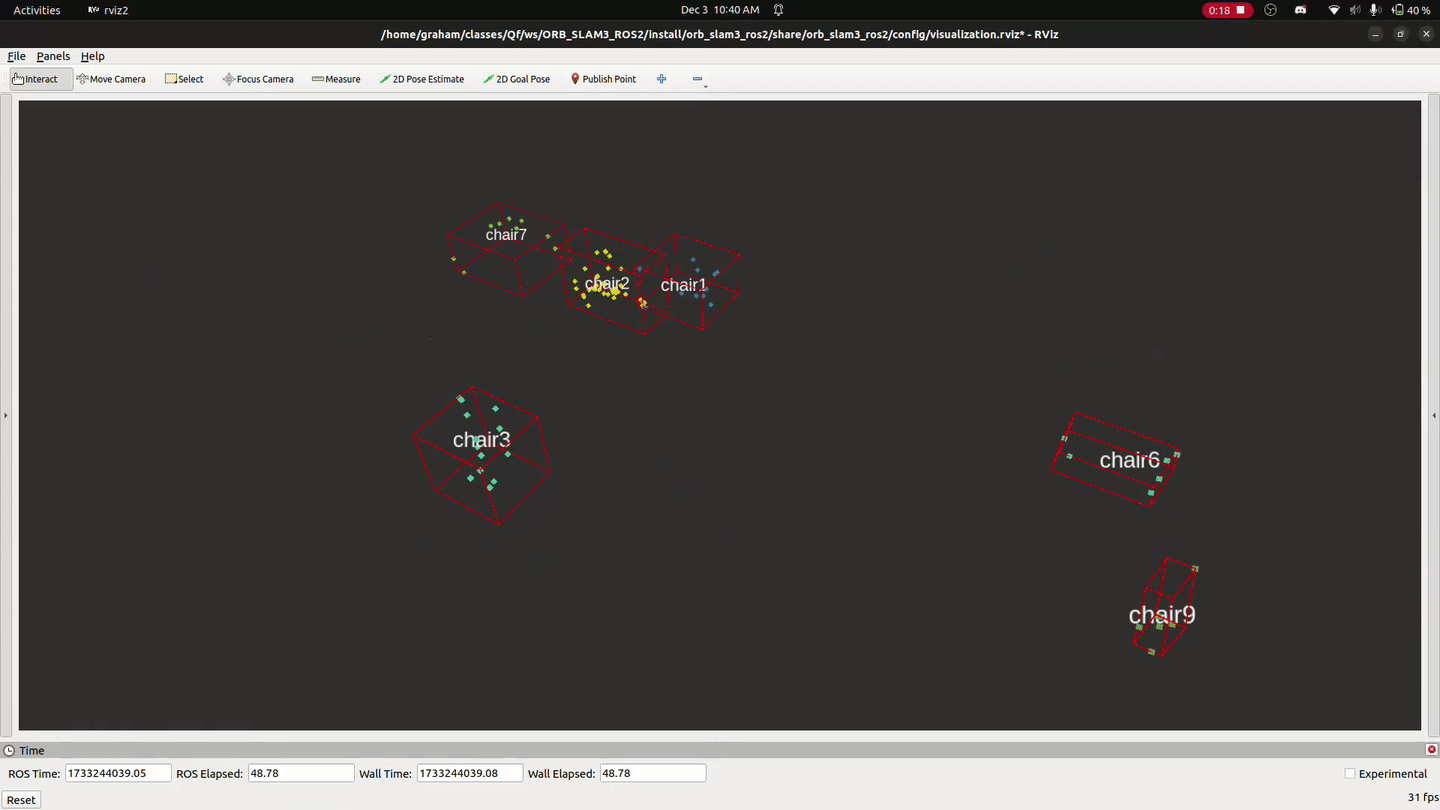
Localization
Adaptive Monte-Carlo Localization (AMCL) is used to localize the LUCI wheelchair in the semantic maps. This strategy requires a 2D lidar scan, a 2D occupancy grid map, odometry, and the initial pose of the robot in the map.
The 2D lidar scan is created from the front right and front left infrared cameras on the LUCI wheelchair. The 3D point clouds from the infrared cameras are collapsed down and filtered into 2D lidar scans using the ROS2 package pointcloud_to_laserscan.
The 2D occupancy grid map is created from the semantic map that we created with the dockerized CMake package. It’s the result of running a couple different filters on the 3D point cloud (statistical outlier removal, radius outlier removal, voxel grid downsampling, and passthrough filtering) and then projecting the points onto a 2D grid.
The odometry is created from the wheel encoders on the LUCI wheelchair. The wheel encoders are used to calculate the distance the wheelchair has traveled and the angle it has turned. This information is used to update the robot’s transform from the “odom” frame to the “base_link” frame, which is required by AMCL and ROS REP 105.
Navigation
The LUCI wheelchair is navigated through the semantic maps using the ROS2 package Nav2. Landmarks detected in the semantic mapping stage are display on the map within RVIZ, and navigation goals are set by placing them manually on the map within RVIZ.
This package integrates with the final project of another student, Rintaroh Shima. Landmarks discovered during semantic mapping can be loaded into his PyQt GUI application on a tablet, and the tablet can be used to set navigation goals for the wheelchair. His package also allows for the creation of new landmarks by performing object recognition with the cameras on the wheelchair durinig localization. You can learn more and watch a demo of his package here.
Further work is needed to refine the navigation system. Here’s an example of it’s state as of 12-05-2024:
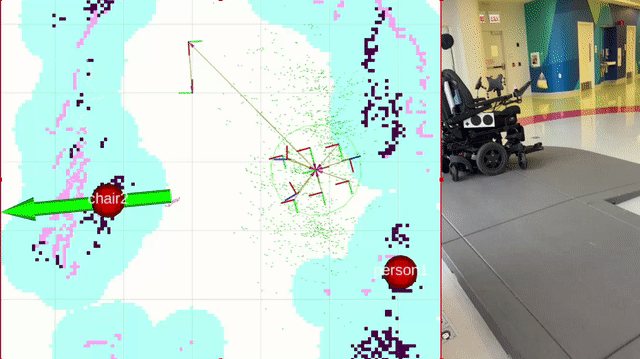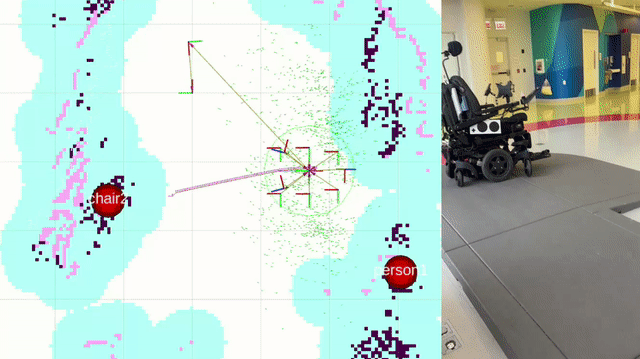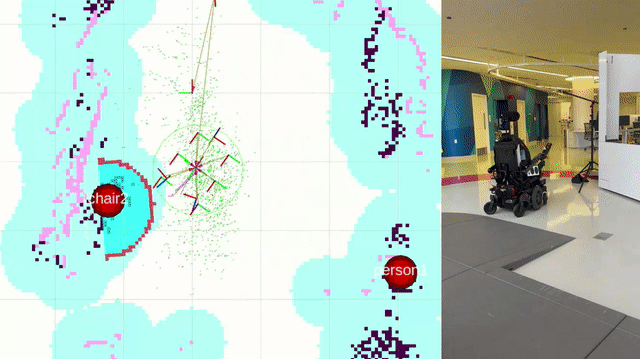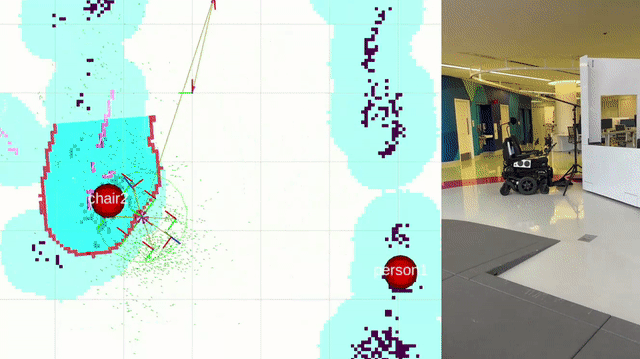
Future Work
There are multiple possible areas of future work for this project.
- Create Manual Labeling Tool: A tool that allows users to manually label objects in the semantic map would be useful for editing the labels of objects detected by the YOLOv8 model, and the addition of custom landmarks. I am actively working on this tool, and it will be complete before 01-01-2025.
- Improve Object Detection: The YOLOv8 model used for object detection is simply one of the default models, yolov8m. It would be beneficial to build on this model and train it to recognize additional common household objects.
- Improve Localization: The localization system could be improved by using further tuning of the AMCL parameters. It is also possible to use RTABMap for localization on the wheelchair, and localize directly in the maps created by the iPhone.
- Improve Navigation: The navigation system could be improved by performing additional tuning of the Nav2 parameters.
Acknowledgements
Thank you to Professor Argall, Matt, Larisa, Joel, Demiana, Fiona, and Andrew for their help and guidance on this project.
Here’s a link to the full video of my localization session on 12-10-2024. This session was used to make the gifs of localization in this post: